🎄 Happy Holidays! 🥳
Most of Solace is closed December 24–January 1 so our employees can spend time with their families. We will re-open Thursday, January 2, 2024. Please expect slower response times during this period and open a support ticket for anything needing immediate assistance.
Happy Holidays!
Please note: most of Solace is closed December 25–January 2, and will re-open Tuesday, January 3, 2023.
HA redundancy - Monitoring node issue

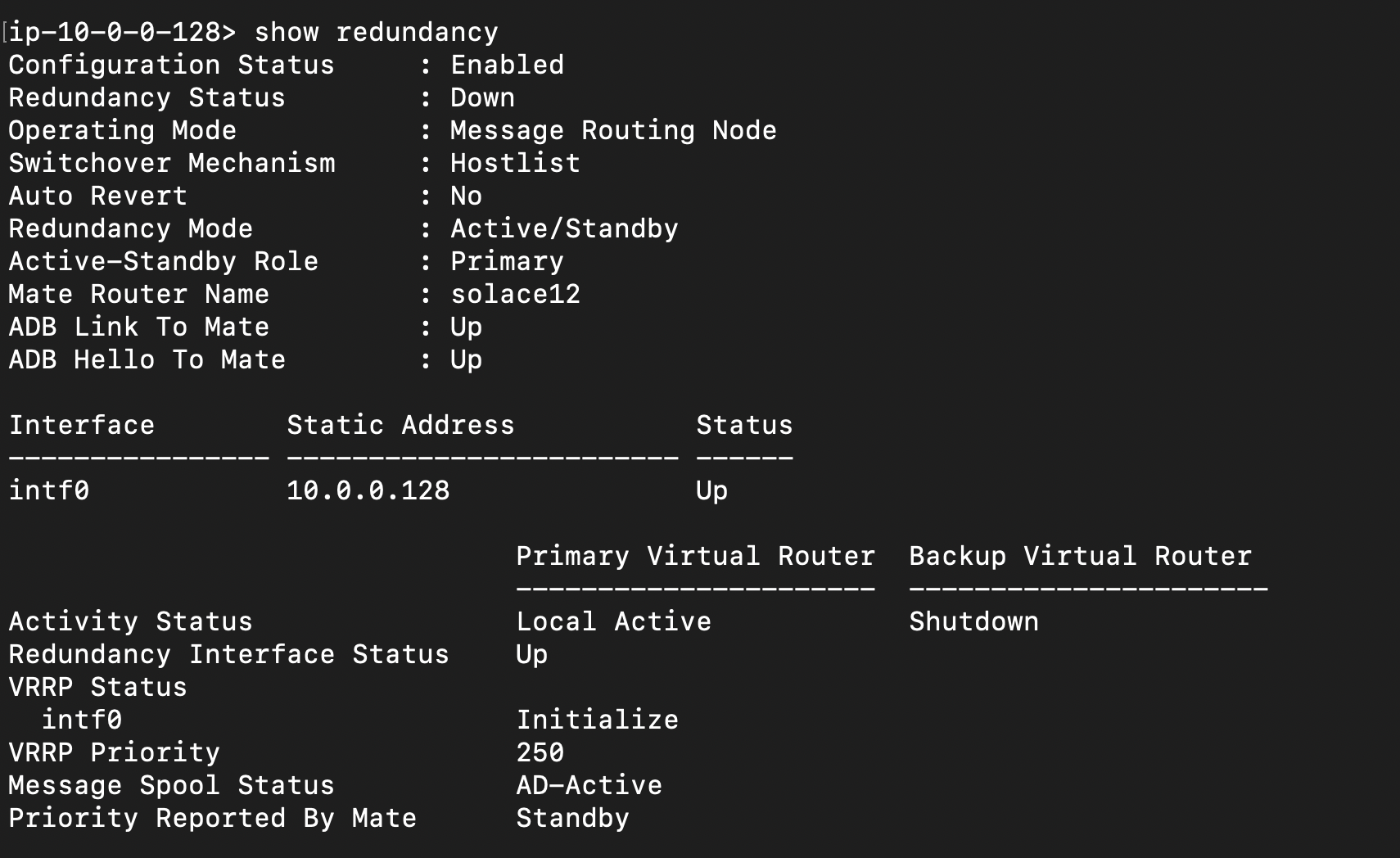
I followed the steps documented in the HA redundancy section, both the primary and backup nodes are online and I can see the redundancy working.
Monitoring node is offline, the show redundancy group on monitoring node shows all nodes as offline.
I tried multiple times the behaviour is consistent, not sure what I am missing.
Thanks
Madhu
Comments
-
I observe the below error message on the monitoring node debug log. Not exactly sure what does it mean, I just performed the steps provided in the documentation no customization performed on any node.
2023-04-26T05:52:56.174+00:00 <local0.err> ip-10-0-0-126 appuser[387]: /usr/sw ConsulFSM.cpp:860 (REDUNDANCY - 0x0000000
0) ConsulProxyThread(9)@controlplane(10) ERROR Could not determine self node configuration
2023-04-26T05:52:57.175+00:00 <local0.err> ip-10-0-0-126 appuser[387]: /usr/sw ConsulFSM.cpp:860 (REDUNDANCY - 0x0000000
0) ConsulProxyThread(9)@controlplane(10) ERROR Could not determine self node configuration
2023-04-26T05:52:58.176+00:00 <local0.err> ip-10-0-0-126 appuser[387]: /usr/sw ConsulFSM.cpp:860 (REDUNDANCY - 0x0000000
0) ConsulProxyThread(9)@controlplane(10) ERROR Could not determine self node configuration
2023-04-26T05:52:59.177+00:00 <local0.err> ip-10-0-0-126 appuser[387]: /usr/sw ConsulFSM.cpp:860 (REDUNDANCY - 0x0000000
0) ConsulProxyThread(9)@controlplane(10) ERROR Could not determine self node configuration
Thanks
Madhu
0 -
Hahaha, no worries, that's muscle memory I guess ;)
Good to hear it got solved!
As added note, there are options to use helm charts, docker compose, cloud formation, etc. that might help automate these steps. Or even better, just use solace.com/cloud if you just need a broker that just runs ;)
0 -
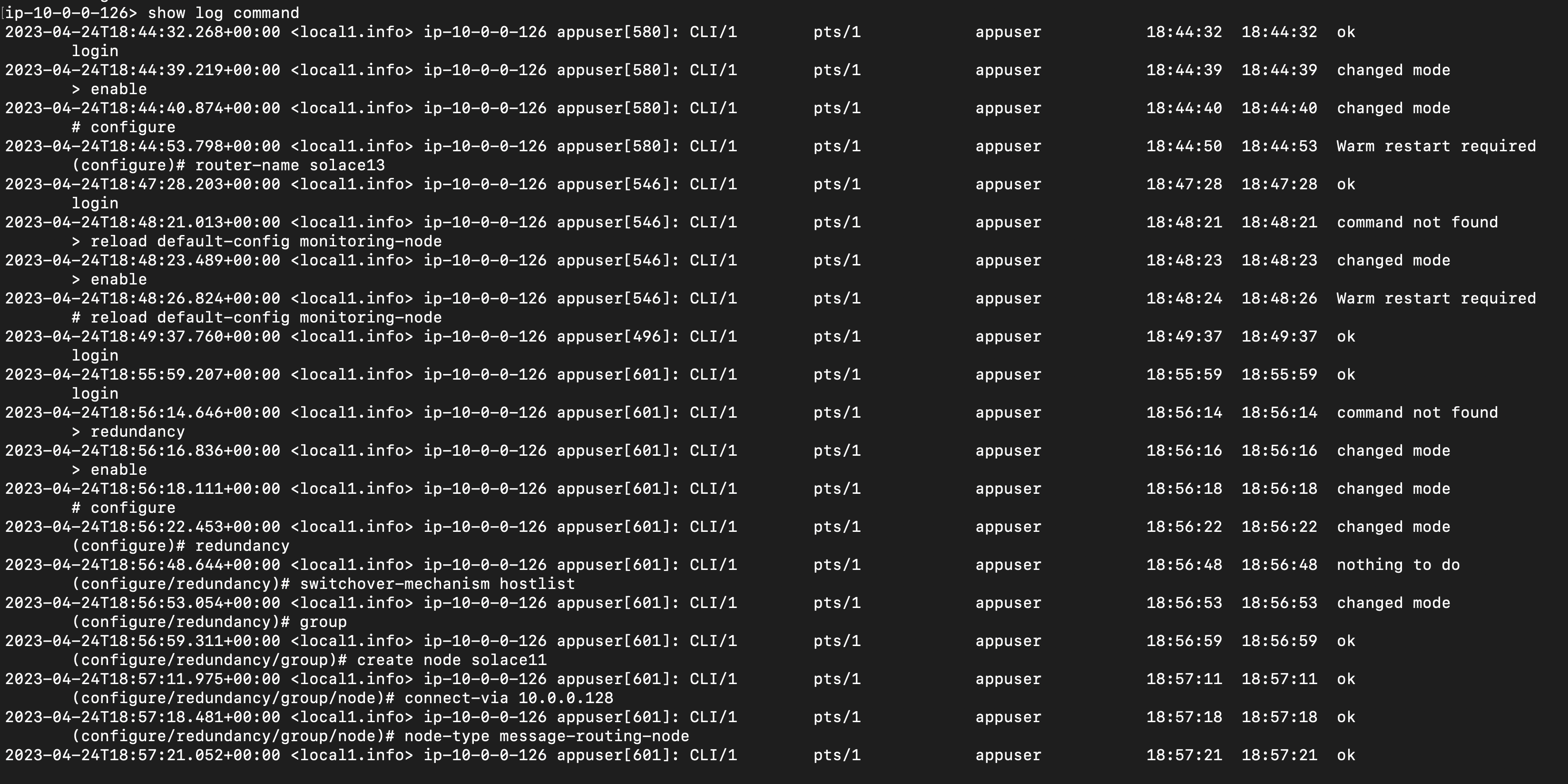
Looking at your CLI output, I can see you setting the router-name and then reloading the default config. Which essentially completely replaces all configuration with whatever is stored internally as default. So yeah, it would have overwritten the router name that you set.
I've raised a documentation enhancement for the page you cited in your first post.
0